How to run opensource LLM's locally
Here’s a quick guide to getting open-source large language models (LLMs) running and testable on your local Linux computer using Ollama. We’ll walk through installing Ollama, setting up a model, and creating a Node.js client for testing.
Step 1: Install Ollama
Install Ollama with the following command, which downloads and configures a repository, installs the Ollama service, and sets it to start at boot. This script also checks if you have a compatible NVIDIA or AMD GPU, installing CUDA libraries when needed.
sudo curl -fsSL https://ollama.com/install.sh | sh
This is the output of the command on a Rocky 9 virtual machine.
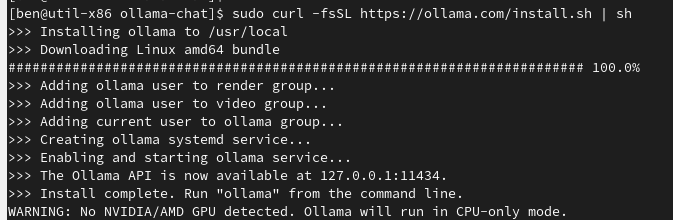
Step 2: Verify Ollama installation
Once Ollama is installed and running, you can test it by listing available models:
ollama list
If no models are installed yet, you’ll see an empty list:

Step 3 Download a model
Now let’s install a lightweight model. We’ll use tinydolphin for its speed and low resource requirements.
ollama pull tinydolphin
ollama list
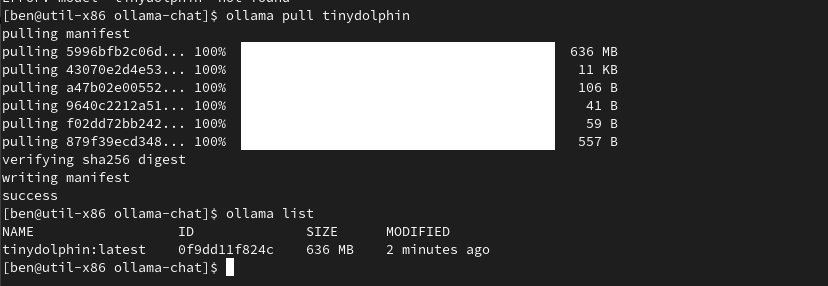
We see that we now have downloaded tinydolphin and it is ready to use.
To install other models with specific parameter sizes, use a command like this:
ollama pull llama3.1:8b
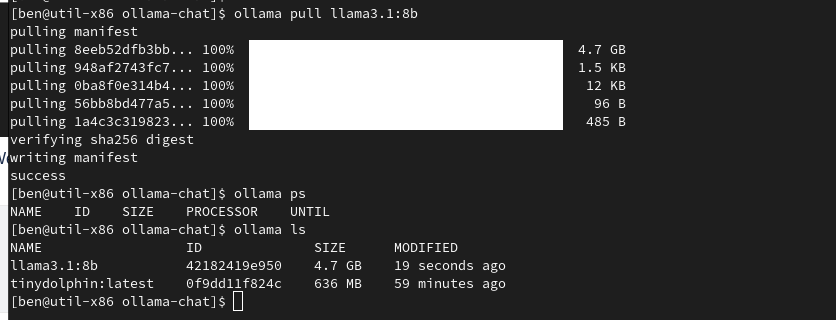
Step 4 Testing the Model with a Basic Request
You can test the model directly using a curl command:
curl http://localhost:11434/api/generate -d '{
"model": "tinydolphin",
"prompt": "Have you ever been to CyberOblivion?"
}'
The output from this command is functional but not easy to read. Let’s improve this by creating a Node.js client that could be expanded for real-world applications.
Building a Node.js Client for Ollama
Step 5 Install Node.js 20
If you’re on Fedora 40, Node.js 20 is the default, but for other distributions, you might need to install it manually. On Rocky 9, RHEL 9, or similar, use the following:
curl -fsSL https://rpm.nodesource.com/setup_20.x | sudo bash -
Step 6 Create a Node.js Project and Client Script
1. Setup the project
mkdir -p ~/dev/projects/ollama-chat
cd ~/dev/projects/ollama-chat
npm init -y
sudo npm install ollama
2. Create ask.js with the following code
import { Ollama } from 'ollama';
// Capture the command-line argument, assuming the first argument after `node index.js "<your_text>"` is the input: be sure to put the text in quotes.
const inputText = process.argv[2]; // This will be the command-line argument
// Check if input is provided
if (!inputText) {
console.error("Please provide text as a command-line argument.");
process.exit(1);
}
const ollama = new Ollama({ host: 'http://127.0.0.1:11434' });
async function chatWithModel() {
try {
const response = await ollama.chat({
model: 'tinydolphin',
messages: [{ role: 'user', content: inputText }], // Send the command-line input
});
console.log("Response from Ollama:", response); // Log the response
} catch (error) {
console.error('Error chatting with model:', error); // Log any errors
}
}
chatWithModel();
3. Update package.json to include "type": "module",:
{
"name": "ollama-chat",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"ollama": "^0.5.9"
}
}
Step 7: Run the client
Now you can chat with the AI! Run the client to ask the model a question. Be sure to enclose the question in quotes:
node ask.js "Have you ever been to CyberOblivion?"
You should receive a response like this:
{
"model": "tinydolphin",
"created_at": "2024-11-01T17:38:17.895120217Z",
"message": {
"role": "assistant",
"content": "Yes, I have visited Cyberoblivion once. It was quite an interesting experience! The people there were very friendly and the atmosphere of the place was fascinating. They had exhibits that showed how technology has evolved over the years, and it was a great opportunity to learn about new innovations in cyberspace. Additionally, I enjoyed the various activities and games they had available, such as painting with words and playing virtual concerts. Overall, it was a great experience, and I would definitely recommend visiting Cyberoblivion for anyone who has a interest in technology or wants to learn more about its future."
},
"done_reason": "stop",
"done": true,
"total_duration": 3291232310,
"load_duration": 5676635,
"prompt_eval_count": 40,
"prompt_eval_duration": 425389000,
"eval_count": 73,
"eval_duration": 2731764000
}
Wrapping Up
With Ollama and a client set up, you now have a local environment for experimenting with LLMs! Running models like tinydolphin locally can save costs, enhance data privacy, and provide a playground for building custom AI applications.
Stick around coming up we’re going to show how to create and use embeddings!
Back to the hacks!